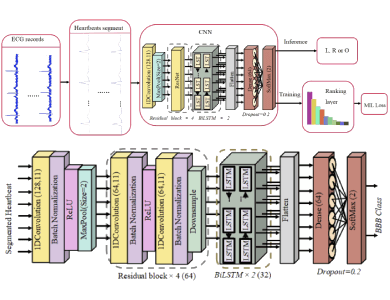
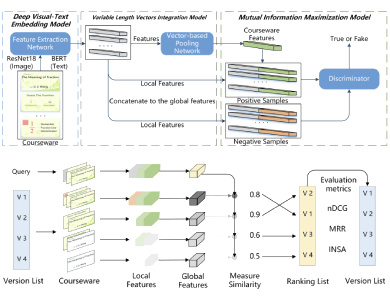
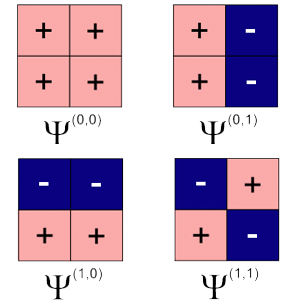
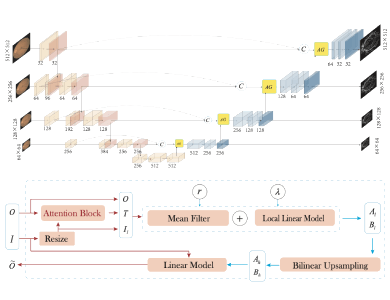
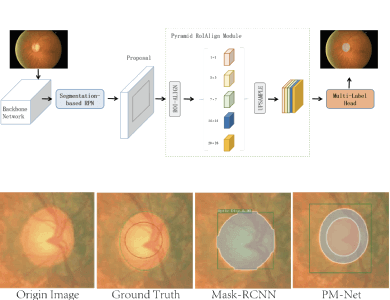
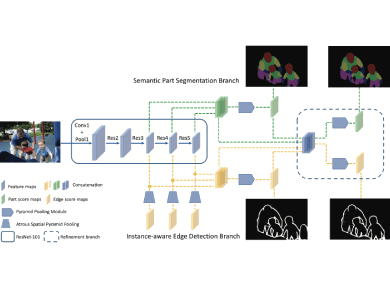
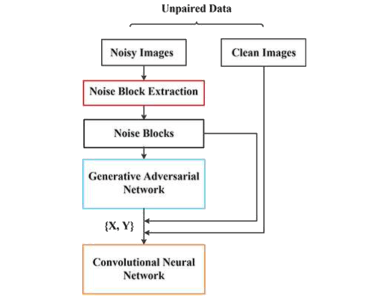
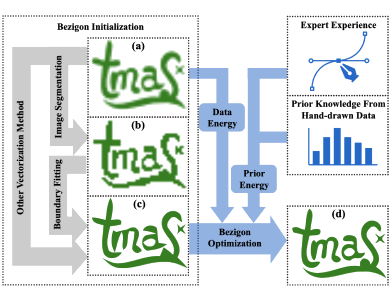
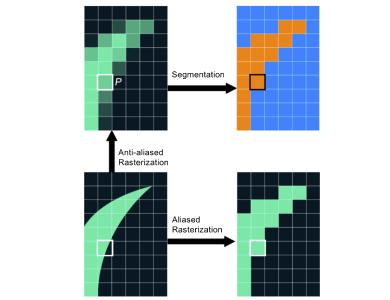
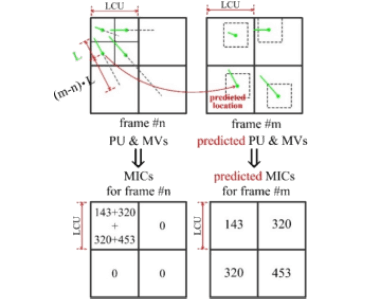
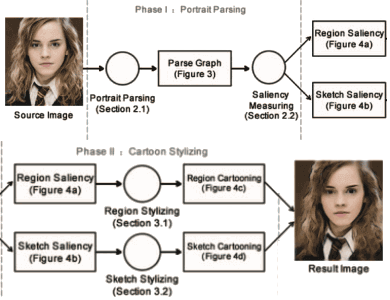
Dr. Ming Yang
Ming Yang is a CTO with CVTE (002841.SZ), where he also serves as a Director of CVTE Research. His team is focusing on the research, development, and innovation of perception AI (vision, speech, haptics, etc.), with a broad range of applications in smart manufacturing, future education, and corporate services.
Prior to joining CVTE, Ming received a B.E. (2009) and a Ph.D. (2014, advised by Prof. Hongyang Chao) in Computer Science from Sun Yat-sen University. He has spent time at Microsoft Research Asia (2010 ~ 2012, advised by Jian Sun who lead the Visual Computing Group).